
Problem Statement
Our company website has been running on PHP + WordPress for years, but it’s time to leave behind plugin roulette, limited extensibility, and the burden of maintaining a non-Python backend.
We wanted a single Python codebase where we could:
- Keep a first‑class CMS experience for non‑technical editors.
- Share one auth/session layer across future Django apps that want to implement.
Django was the obvious framework home, but which CMS layer? We compared Mezzanine, Django‑CMS, plain Django admin plus custom forms, and Wagtail. Wagtail won thanks to:
- StreamField – Gutenberg‑style flexibility with structured data.
- Image & media pipeline – renditions, focal‑point cropping, WebP out of the box.
- Polished editor UI – non‑devs can hit Save & Publish confidently.
- Lightweight architecture – everything is just Django models, views, and templates; no plugin maze.
The rest of this post shows how we migrated, step‑by‑step, while retaining the parts WordPress we liked and unlocking Django’s app‑building capabilities.
1. Why Django Wagtail Instead of Plain Django
| Concern | Plain Django | Django Wagtail |
|---|---|---|
| Editor UI | Build your own admin or rely on stock Django admin (not CMS‑friendly). | Polished CMS dashboard, StreamField blocks, image chooser, preview. |
| Rich Content | Custom models + custom forms. | StreamField = Gutenberg‑style flexibility with structured data. |
| Media & Images | Write your own thumbnail / rendition logic. | Built‑in image renditions, focal‑point cropping, collections. |
| SEO / Redirects | Add 3rd‑party libs. | First‑party wagtailseo, wagtailredirects. |
| Menus / Snippets | Roll your own. | wagtailmenus, snippets chooser panels. |
| Upgrade cadence | Django LTS only. | Django + Wagtail LTS; Wagtail’s editor features evolve faster. |
Bottom line: Wagtail adds the CMS layer so you don’t reinvent page editing, yet you still write pure Django under the hood.
2. What you need to do in Django:
Here we will cover only the essential parts that are easy to get wrong. As the most important task, you will need to declare the models which you will use to store the data coming from WordPress.
# blog/models.py
from django.db import models
from modelcluster.contrib.taggit import ClusterTaggableManager
from modelcluster.fields import ParentalKey, ParentalManyToManyField
from taggit.models import TaggedItemBase
from wagtail.admin.panels import FieldPanel, InlinePanel
from wagtail.fields import RichTextField
from wagtail.models import Page
# ----------------- Authors -----------------
class BlogAuthor(models.Model):
wp_id = models.PositiveIntegerField(unique=True) # maps 1‑to‑1 with wp_users.ID
name = models.CharField(max_length=255)
email = models.EmailField()
panels = [FieldPanel("name"), FieldPanel("email")]
def __str__(self):
return self.name
# ----------------- Categories -----------------
class BlogCategory(models.Model):
name = models.CharField(max_length=255)
slug = models.SlugField(unique=True)
panels = [FieldPanel("name"), FieldPanel("slug")]
def __str__(self):
return self.name
# ----------------- Tags -----------------
class BlogPageTag(TaggedItemBase):
content_object = ParentalKey(
"blog.BlogPage", related_name="tagged_items", on_delete=models.CASCADE
)
# ----------------- Blog index -----------------
class BlogIndexPage(Page):
intro = RichTextField(blank=True)
content_panels = Page.content_panels + [FieldPanel("intro")]
parent_page_types = ["home.HomePage"]
subpage_types = ["blog.BlogPage"]
class Meta:
verbose_name = "Blog Index Page"
# ----------------- Individual post -----------------
class BlogPage(Page):
date = models.DateField("Post date")
author = models.ForeignKey(
"blog.BlogAuthor", null=True, blank=True, on_delete=models.SET_NULL
)
cover_image = models.ForeignKey(
"wagtailimages.Image", null=True, blank=True, on_delete=models.SET_NULL, related_name="+"
)
body = RichTextField(blank=True)
categories = ParentalManyToManyField("blog.BlogCategory", blank=True)
tags = ClusterTaggableManager(through=BlogPageTag, blank=True)
content_panels = Page.content_panels + [
FieldPanel("date"),
FieldPanel("author"),
FieldPanel("cover_image"),
FieldPanel("body"),
FieldPanel("categories"),
FieldPanel("tags"),
InlinePanel("post_comments", label="Comments"),
]
class Meta:
verbose_name = "Blog Post"
# ----------------- Comments -----------------
class BlogComment(models.Model):
post = ParentalKey(
"blog.BlogPage", related_name="post_comments", on_delete=models.CASCADE
)
author = models.CharField(max_length=255)
email = models.EmailField(blank=True)
content = models.TextField()
approved = models.BooleanField(default=False)
date = models.DateTimeField(auto_now_add=True)
parent = models.ForeignKey("self", null=True, blank=True, on_delete=models.SET_NULL)
panels = [
FieldPanel("author"),
FieldPanel("email"),
FieldPanel("content"),
FieldPanel("approved"),
]
def __str__(self):
return f"Comment by {self.author} on {self.post.title}"Why these choices?
wp_idonBlogAuthorlets the XML import map authors flawlessly.ParentalManyToManyFieldkeeps category edits inline—no admin hopping.RichTextFieldfor body keeps import simple; later we can convert to StreamField blocks if we need richer layouts.- Comments live as a child relation so editors can moderate without leaving the post.
With models in place, we can now parse XML and hydrate these objects—next section shows the command that does exactly that.
3. XML Import Pain — Why Existing Libraries Fell Short
Before reaching for xmltodict, we trial‑ran every library we could find:
| Library | Status in 2025 | Deal‑Breaker |
wagtail-wordpress-import | Alpha, opinionated | Tied to their demo models; mis‑mapped our categories |
wagtail-transfer | Production‑ready—but Wagtail → Wagtail | Not designed for WordPress |
django-import-export | Generic fixtures | Knows nothing about WordPress schema |
After three evenings of trial‑and‑error, the verdict was clear: roll our own once, run it forever.
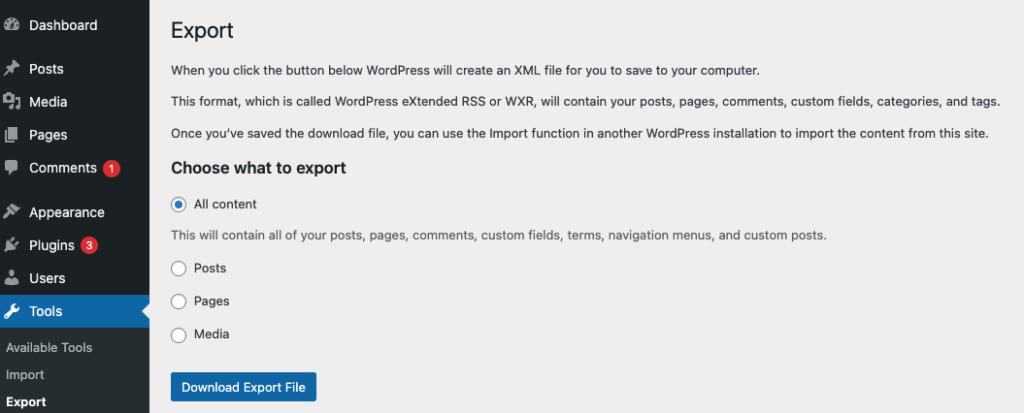
Export your Data from WordPress
Simply go to your WordPress Dashboard and go to “Tools” and select “All content” and click on “Downliad Export File” as shown below.
Our Custom Management Command
After wrestling with half‑maintained libraries, we wrote a single management command that:
- Parses WordPress XML via
ElementTree(faster, no type leaks). - Cleans messy HTML with BeautifulSoup + Bleach so Wagtail’s rich‑text import never chokes.
- Imports authors, categories, tags, cover images, and nested comments in two passes (first create, then parent‑link).
# blog/management/commands/import_wordpress.py
import html
import xml.etree.ElementTree as ET
from datetime import datetime
from email.utils import parsedate_to_datetime
import bleach
from blog.models import BlogCategory, BlogComment, BlogIndexPage, BlogPage
from bs4 import BeautifulSoup
from django.core.management.base import BaseCommand
from django.utils import timezone
from django.utils.dateparse import parse_datetime
from django.utils.text import slugify
from wagtail.models import Page
# --- Extra imports for author and cover image handling
import requests
import os
from django.core.files.base import ContentFile
from wagtail.images.models import Image
from blog.models import BlogAuthor
# Namespaces for WordPress XML
ns = {
"content": "http://purl.org/rss/1.0/modules/content/",
"dc": "http://purl.org/dc/elements/1.1/",
"wp": "http://wordpress.org/export/1.2/",
}
# ------------------------------------------------------------------
# Clean up WordPress HTML so Wagtail's rich‑text converter doesn't
# choke on orphan <li> tags or other malformed markup.
ALLOWED_TAGS = [
"p",
"br",
"strong",
"em",
"a",
"ul",
"ol",
"li",
"blockquote",
"h1",
"h2",
"h3",
"h4",
"h5",
"h6",
"img",
"pre",
"code",
"hr",
]
ALLOWED_ATTRS = {"a": ["href", "title"], "img": ["src", "alt"]}
def clean_wp_html(raw: str) -> str:
soup = BeautifulSoup(raw or "", "html.parser")
# Wrap orphan <li> in <ul>
for li in soup.find_all("li"):
if li.parent.name not in ("ul", "ol"):
wrapper = soup.new_tag("ul")
li.wrap(wrapper)
# Normalise <br> tags to self‑closing <br /> so Wagtail's converter
# doesn't confuse an implicit </br> close.
for br in soup.find_all("br"):
br.attrs = {} # strip any stray attributes
cleaned = bleach.clean(
str(soup),
tags=ALLOWED_TAGS,
attributes=ALLOWED_ATTRS,
strip=True,
)
# Replace any <br></br> or <br> pairs that slipped through with a self‑closing tag.
cleaned = cleaned.replace("<br></br>", "<br />").replace("<br>", "<br />")
return cleaned
# ------------------------------------------------------------------
class Command(BaseCommand):
help = "Import WordPress blog posts and comments from XML export"
def add_arguments(self, parser):
parser.add_argument("xml_file", type=str, help="Path to WordPress XML file")
def handle(self, *args, **kwargs):
xml_file = kwargs["xml_file"]
tree = ET.parse(xml_file)
root = tree.getroot()
# Preload WordPress authors
authors_map = {}
for author in root.findall("./channel/wp:author", ns):
login = author.findtext("wp:author_login", namespaces=ns)
authors_map[login] = {
"id": author.findtext("wp:author_id", namespaces=ns),
"name": author.findtext("wp:author_display_name", namespaces=ns),
"email": author.findtext("wp:author_email", namespaces=ns),
}
# Preload attachments for cover images
attachments_map = {}
for item in root.findall("./channel/item"):
if item.findtext("wp:post_type", namespaces=ns) == "attachment":
attachments_map[item.findtext("wp:post_id", namespaces=ns)] = item.findtext("wp:attachment_url", namespaces=ns)
# Map post ID to cover URL via _thumbnail_id postmeta
thumbnail_map = {}
for item in root.findall("./channel/item"):
if item.findtext("wp:post_type", namespaces=ns) == "post":
post_id = item.findtext("wp:post_id", namespaces=ns)
for pm in item.findall("./wp:postmeta", namespaces=ns):
if pm.findtext("wp:meta_key", namespaces=ns) == "_thumbnail_id":
thumb_id = pm.findtext("wp:meta_value", namespaces=ns)
thumbnail_map[post_id] = attachments_map.get(thumb_id)
# Helper: generate a unique slug (≤255 chars) among the BlogIndexPage’s children
def _generate_unique_slug(parent_page, title):
base_slug = slugify(title)[:255] or "post"
slug = base_slug
suffix = 1
while parent_page.get_children().filter(slug=slug).exists():
slug = f"{base_slug}-{suffix}"
suffix += 1
return slug
# Get BlogIndexPage (must be created manually first)
try:
blog_index = BlogIndexPage.objects.first()
if not blog_index:
self.stderr.write(
"❌ No BlogIndexPage found. Please create one in the Wagtail admin first."
)
return
except BlogIndexPage.DoesNotExist:
self.stderr.write("❌ BlogIndexPage model not defined.")
return
for item in root.findall("./channel/item"):
post_type = item.find("./wp:post_type", ns)
if post_type is not None and post_type.text == "post":
# Capture this post’s ID
wp_post_id = item.findtext("wp:post_id", namespaces=ns)
title = item.findtext("title")
raw_body = html.unescape(item.find("content:encoded", ns).text or "")
content = clean_wp_html(raw_body)
pub_date = item.findtext("pubDate")
# Parse publication date (WordPress uses RFC 2822). Fallback to now().
try:
parsed_date = parsedate_to_datetime(pub_date) if pub_date else None
except (TypeError, ValueError):
parsed_date = None
if parsed_date is None:
parsed_date = timezone.now()
# --- WordPress author mapping
login = item.findtext("dc:creator", namespaces=ns)
author_data = authors_map.get(login)
if author_data:
author_obj, _ = BlogAuthor.objects.get_or_create(
wp_id=author_data["id"],
defaults={"name": author_data["name"], "email": author_data["email"]},
)
else:
author_obj = None
categories = [
c.text
for c in item.findall("category")
if c.get("domain") == "category"
]
tags = [
t.text
for t in item.findall("category")
if t.get("domain") == "post_tag"
]
blog_page = BlogPage(
title=title,
slug=_generate_unique_slug(blog_index, title),
author=author_obj,
body=content,
date=parsed_date.date(),
)
# Attach and save the blog page
blog_index.add_child(instance=blog_page)
blog_page.save() # Ensure instance is saved first
# Import cover image if available
cover_url = thumbnail_map.get(wp_post_id)
if cover_url:
try:
resp = requests.get(cover_url)
resp.raise_for_status()
image_name = os.path.basename(cover_url)
image_file = ContentFile(resp.content, name=image_name)
wagtail_image = Image.objects.create(title=f"Cover for {title}", file=image_file)
blog_page.cover_image = wagtail_image
blog_page.save(update_fields=["cover_image"])
except Exception as e:
self.stderr.write(f"Failed to import cover image for {title}: {e}")
# Tags (ClusterTaggableManager handles creation)
if tags:
blog_page.tags.add(*tags)
for cat in categories:
category_obj, _ = BlogCategory.objects.get_or_create(
slug=slugify(cat), defaults={"name": cat}
)
blog_page.categories.add(category_obj)
# Final save and publish
blog_page.save()
blog_page.save_revision().publish()
# ——— prepare to map WordPress comment IDs → BlogComment objects
comments_map = {}
# First pass: create comments without parents
for comment in item.findall("./wp:comment", ns):
# Ignore pingbacks / trackbacks (WordPress marks them via <wp:comment_type>)
ctype = comment.findtext(
"wp:comment_type", default="", namespaces=ns
)
if ctype and ctype.strip() not in ("", "comment"):
continue
wp_comment_id = comment.findtext("wp:comment_id", namespaces=ns)
parent_wpid = (
comment.findtext("wp:comment_parent", namespaces=ns) or None
)
comment_obj = BlogComment.objects.create(
post=blog_page,
author=comment.findtext(
"wp:comment_author", default="", namespaces=ns
),
email=comment.findtext(
"wp:comment_author_email", default="", namespaces=ns
),
date=timezone.make_aware(
parse_datetime(
comment.findtext("wp:comment_date", namespaces=ns)
)
or datetime.now()
),
content=html.unescape(
comment.findtext(
"wp:comment_content", default="", namespaces=ns
)
),
approved=comment.findtext("wp:comment_approved", namespaces=ns)
== "1",
parent=None, # set later
)
comments_map[wp_comment_id] = (comment_obj, parent_wpid)
# Second pass: hook up parent relationships now that all comments exist
for wp_comment_id, (comment_obj, parent_wpid) in comments_map.items():
if parent_wpid and parent_wpid in comments_map:
parent_obj, _ = comments_map[parent_wpid]
comment_obj.parent = parent_obj
comment_obj.save(update_fields=["parent"])
self.stdout.write(
f" ↳ Imported {len(comments_map)} comments, {len(tags)} tags, {len(categories)} categories for '{title}'"
)
self.stdout.write(self.style.SUCCESS(f"✅ Imported post: {title}"))
self.stdout.write(
self.style.SUCCESS("All blog posts and comments imported successfully.")
)
You can run that script using:
python manage.py import_wordpress /path/to/wordpress.xml4. How can you make Wagtail have a WordPress-like experience?
Must-have:
| WordPress Feature | Wagtail Equivalent | Why You Probably Need It |
| Permalink structure | wagtailredirects, custom Route mixins | Preserve SEO juice & old backlinks. |
| Menus (Appearance → Menus) | wagtailmenus | Drag‑and‑drop nav builder for editors. |
| Yoast SEO | wagtailseo, wagtail-metadata | Title/description previews, OpenGraph tags. |
| Widgets / Sidebars | Snippets + inclusion tags | Recent posts, categories list, etc. |
Nice‑to‑haves:
| WordPress Feature | Wagtail Equivalent | Notes |
| Gutenberg Blocks | Custom StreamField blocks | Re‑create fancy layouts with icons & help‑text. |
| Comments | Disqus embed or wagtail-commenting | Offload spam filtering & moderation. |
| Multilingual (WPML/Polylang) | wagtail-localize | Locale‑aware URLs, translation workflow. |
| Forms (Contact Form 7) | wagtailformblocks or native FormPage | Email hooks, Akismet spam protection. |
5. Conclusion & Key Takeaways
Migrating a mature WordPress site to Django + Wagtail isn’t a weekend hobby project—but it’s far from the multi‑month project many teams would fear.
- Unified Python stack → one deployment pipeline, one set of libraries, easier hiring (if needed).
- Performance & security gains → Core Web Vitals up, plugin exploits down.
- First‑class editor UX → StreamField, image choosers, and drag‑and‑drop menus keep non‑devs happy.
- Custom import pipeline → XML‑to‑Wagtail in minutes, not days, with comments, authors, and media intact.
- Incremental parity roadmap → tackle must‑have packages first, add “nice‑to‑haves” when you’re ready.